

Web Scraping the Ontario Geological Survey
Nitai Dean
2024-12-16
Where did we leave off?
Previously, on Just Scraping By, we dove headfirst into Ontario's geological treasure trove, scraping thousands of Excel files from the OGS website. Thanks to ChatGPT, we automated the process and avoided the mind-numbing fate of manually clicking through endless links.``
But as we all know, the hustle never ends. Now we actually have to visit these webpages and download the data. In the old days, you would need to know what you're doing, but no longer. We're in the age of assistants. So we open our trusty IDE (or ChatGPT interface), and explain the situation. We have all these excel files, with these columns. We can even just load the excel file into ChatGPT and have it see the contents directly. Then we ask ChatGPT to help us build a script that can scrape the data from these webpages. It gives us a rough draft using a python library called Selenium. This actually opens a browser on the computer that is fully controlled by the script, and it can click on links, download files, and even scrape text from the pages. Here is the outline of the script:
excel_files = list(input_dir.glob('**/*.xls*')) print(f"Found {len(excel_files)} Excel files") # split excel files by region excel_files_by_region = {} for excel_file in excel_files: region_name = excel_file.parent.stem if region_name not in excel_files_by_region: excel_files_by_region[region_name] = [] excel_files_by_region[region_name].append(excel_file) driver = setup_selenium() try: for excel_file in tqdm.tqdm(excel_files, desc="Processing Excel files"): process_excel_file_with_selenium(excel_file, ledger, output_dir, driver) finally: driver.quit()
The Selenium Saga
With Selenium, we can now navigate to a page from the Excel file and watch it open in the browser. Want to feel like a hacker? Keep the browser visible. Prefer stealth mode? Run it headless. For now, I’m keeping it visible to scope out the data and figure out what to scrape.
def setup_selenium(): chrome_options = Options() if not OPEN_BROWSER: chrome_options.add_argument("--headless") chrome_options.add_argument("--disable-gpu") chrome_options.add_argument("--no-sandbox") chrome_options.add_argument("--disable-dev-shm-usage") chrome_options.add_argument("--disable-background-timer-throttling") chrome_options.add_argument("--disable-backgrounding-occluded-windows") chrome_options.add_argument("--disable-renderer-backgrounding") service = Service(str(CHROMEDRIVER_PATH)) driver = webdriver.Chrome(service=service, options=chrome_options) return driver
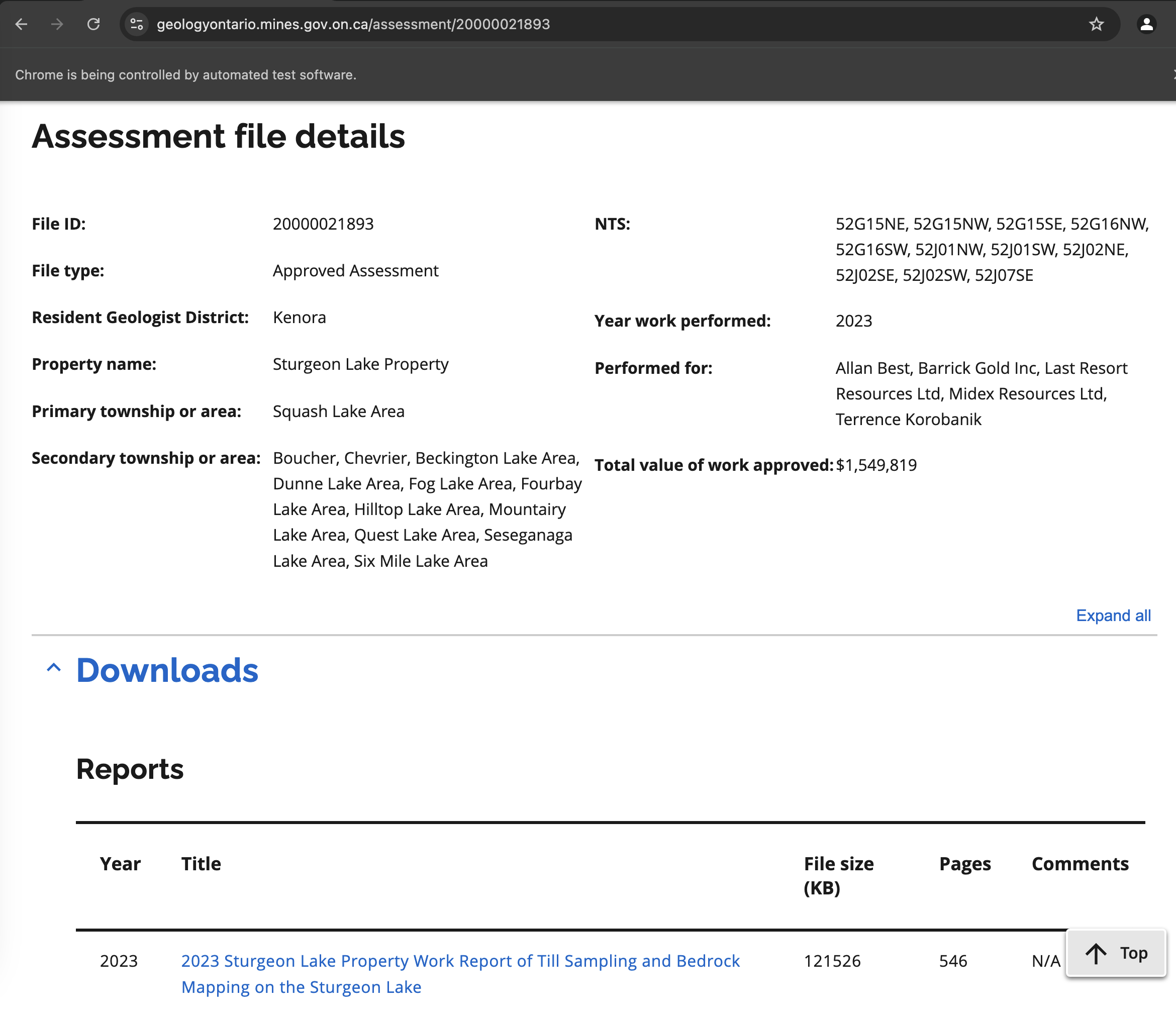 Assessment Files Page
Assessment Files PageDownloading PDFs
Now that we have the page open, we can see that the Downloads section has a link to a PDF file (in general it can have multiple). This is arranged in a table, so we tell ChatGPT to navigate that and download the file. It gives us this:
url = url_template.format(identifier) driver.get(url) try: WebDriverWait(driver, 20).until(EC.presence_of_element_located((By.TAG_NAME, "table"))) except: # noqa print(f"Failed to load page for {identifier}") continue # Extract the tables we care about tables = driver.find_elements(By.TAG_NAME, "table") for table in tables: df_table = pd.read_html(StringIO(table.get_attribute("outerHTML")))[0] table_headers = set(df_table.columns) # download table - get the PDF link for each row if table_headers == {'Pages', 'Comments', 'File size (KB)', 'Year', 'Title'}: rows = table.find_elements(By.TAG_NAME, "tr") for i, row in enumerate(rows[1:]): cells = row.find_elements(By.TAG_NAME, "td") cell_links = [cell.find_elements(By.TAG_NAME, "a") for cell in cells] cell_links = [link for links in cell_links for link in links] if len(cell_links) == 1: df_table.loc[i, "PDF Link"] = cell_links[0].get_attribute("href") download_pdf(cell_links[0].get_attribute("href"), output_dir) filename = cell_links[0].get_attribute("href").split('/')[-1] if not filename.lower().endswith(".pdf"): continue name = f"{region_name.lower()}_{subregion_name.lower()}_{filename[:-4].lower()}" shutil.move(output_dir.joinpath(filename), output_dir.joinpath(f"{name}.pdf"))
This works like a charm: we loop through the tables, find the one with the PDFs, and download them. To stay organized, we rename the files to include the region and subregion names. All this code? Courtesy of Claude. And it just works. One file was over 500 pages, and we snapped it up like a hungry turtle.

Drill Holes
With the assessment file PDFs in hand, we turn to drill hole data — a different beast entirely. No files to download here, but we’ve got a goldmine of metadata that we can link to the PDFs. Check it out:
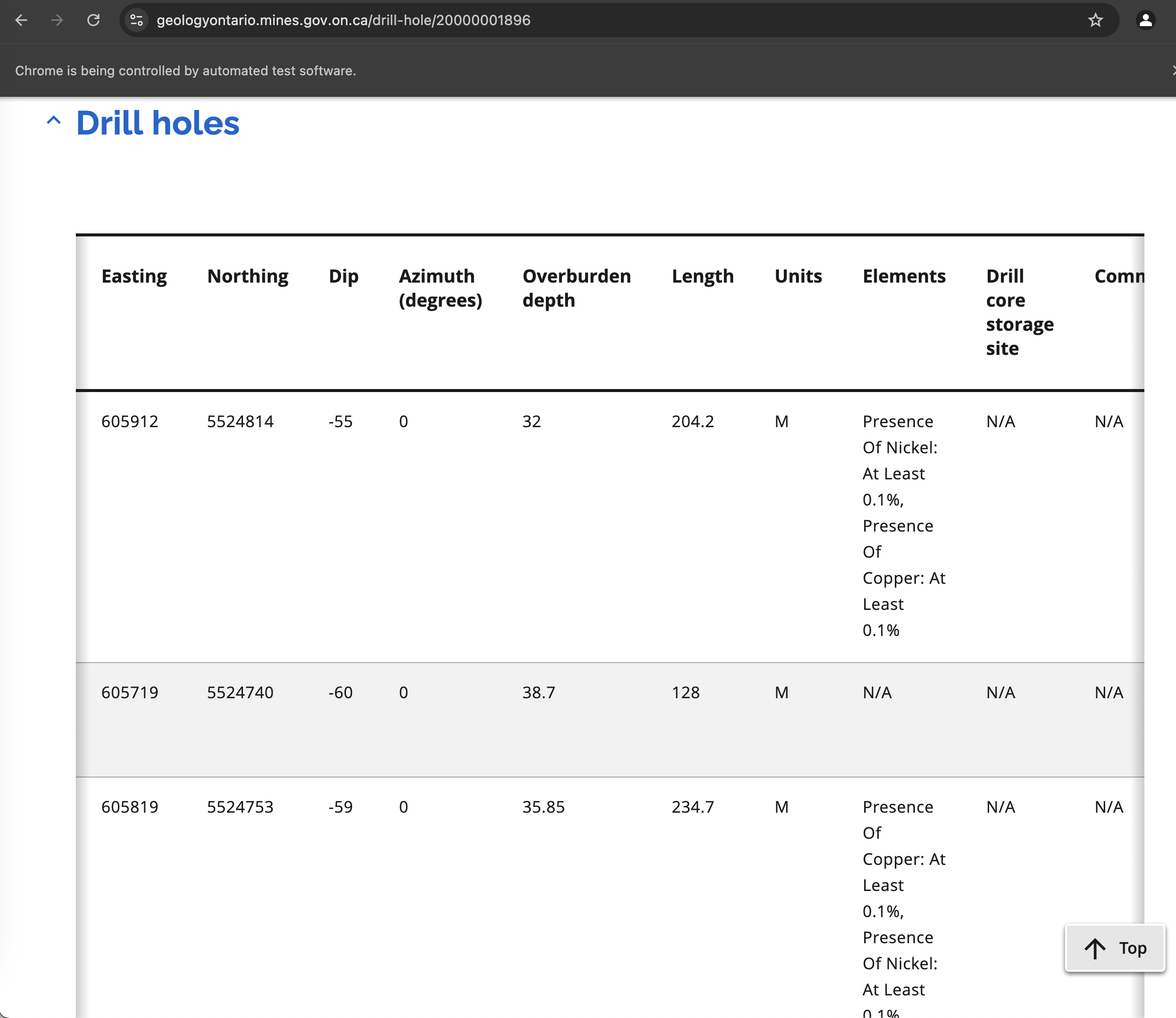 Drill Hole Page
Drill Hole PageThere is wealth of data here: coordinates, minerals that were found, and more. In this case, it's once again in a table, so we can parse it super easily using the pandas function read_html to get it as structured table. We then save it as a JSON file:
df_table = pd.read_html(StringIO(table.get_attribute("outerHTML")))[0] table_headers = set(df_table.columns) # drill hole data table if table_headers == {'Company hole ID', 'UTM zone', 'UTM datum', 'Comments', 'Township or area', 'Easting', 'Azimuth (degrees)', 'Hole Id', 'Overburden depth', 'Hole type', 'Northing', 'Units', 'Elements', 'Drill core storage site', 'Length', 'Dip'}: df_table.to_dict(orient="records") utils.save_json(df_table.to_dict(orient="records"), output_path)
Mineral Inventory
Next up: mineral inventory data. Similar to drill hole data, but focused on the minerals found in the region. This one’s trickier — no tables here, just key/value pairs tucked into collapsible sections. Like this:
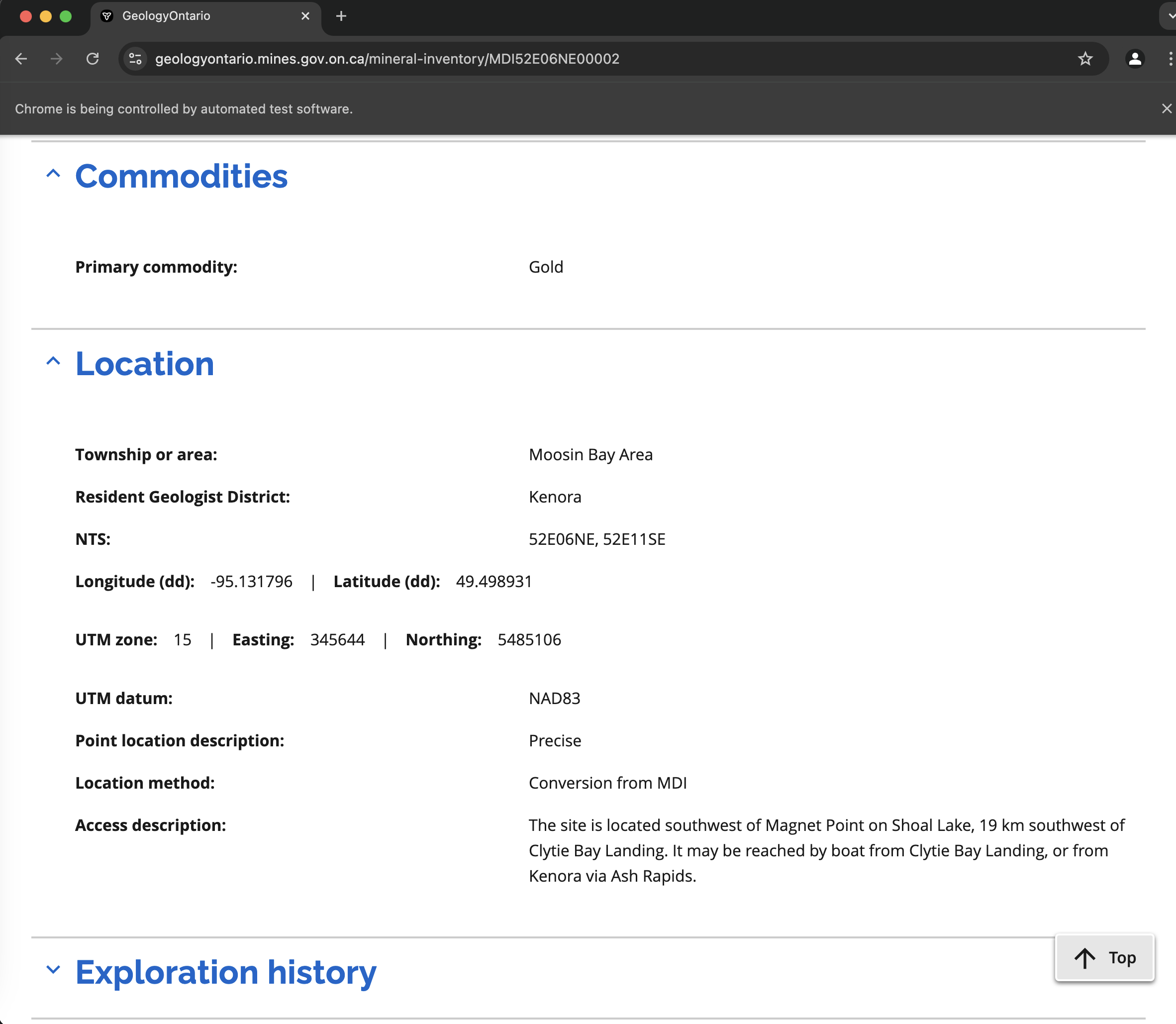 Mineral Inventory Page
Mineral Inventory PageThe reason this is more difficult is because each of these sections begins in a collapsed state, and because it is not arranged in a table, we can't just take the easy way out and use the convenient pandas function read_html. So we need to manually use Chrome inspector to click on the relevant section, and see what HTML elements are being used to show the data. So we do that, and copy paste what we see into ChatGPT. It says that what we're looking for is within a DIV element with certain characteristics, but we first need to simulate a click on the accordion to expand it. It suggests this code, and it works:
other = "" try: button = driver.find_element(By.ID, f"accordion-button-id-{idx}") button.click() except NoSuchElementException: pass divs = driver.find_elements(By.XPATH, "//div[@class='flex mb-0']") for div in divs: text = div.text.strip() if text: other += f"\n{text}" metadata["other"] = other.strip()
So this gives us the non-table metadata in a free text format, which we can add to our JSON metadata. Now, one might think that it is an issue that the data is not in a proper structured format, but that is the power of DocuPanda. Even if the info is just unstructured text, when we standardize it, it will be extracted into a structured format, regardless if the info comes from the PDF contents itself, or any metadata we append alongsides it.
How much is too much?
The data download is cruising along, but we hit a snag: it’s too much. After just 100 Excel files, the gigabytes are piling up faster than my laptop can handle. Time to rethink. ChatGPT suggests a smarter approach: focus only on specific companies. Since our end goal is to try to predict the stock price movements of the big players in the Canadian mining industry, we can limit ourselves to just that subset of data that involves those companies. Claude suggested the regex filter below, applied to the metadata that has company name:
COMPANY_PATTERNS = { "Barrick Gold Corporation": re.compile(r"barrick"), "Newmont Corporation": re.compile(r"newmont"), "Agnico Eagle Mines Limited": re.compile(r"agnico|eagle"), "Vale S.A.": re.compile(r"\bvale\b"), "IAMGOLD Corporation": re.compile(r"iamgold"), "Glencore PLC": re.compile(r"glencore"), "Transition Metals Corp": re.compile(r"transition\s+metals?"), "Northern Superior Resources": re.compile(r"northern\s+superior"), "Benton Resources": re.compile(r"benton"), "GT Resources": re.compile(r"gt\s+resources|palladium\s+one") }
With this filter, we can control the size of the data. Even with only this subset of companies, it still looked like the data was too big - so we ended up limiting it to only a single company: the biggest one, Barrick Gold. It then took around 40 minutes, and we find ourselves with about 9GB of data, spread across 173 PDFs, each accompanied by metadata. This is a good starting point to continue to the next step, and we can always come back and scrape more data with our handy script.
Stay tuned for the next episode, where we dive into exploring the data, organizing it, and standardizing it with DocuPanda.
